Tic Tac Transformer
A few days ago I saw that @davidad had posted that GPT instruct can’t play tic tac toe very well.
So I tried, and it’s true, it’s not so hard to beat.
Unsurprisingly, GPT-4 is very good.
This got me thinking…
What is the smallest transformer that could learn the optimal strategy for tic tac toe?
And how could we train this quickly and efficiently?
Let’s see…
https://github.com/pHaeusler/tic_tac_transformer
Tokenization
Many of the comments on twitter mentioned that tic tac toe does not have a convenient text based representation (or language). This makes it hard for language models to learn how to play. Chess, on the other hand, has algebraic notation, which captures all player moves and board state. And, unsurprisingly, GPT is great at chess.
So let’s make a tiny language for tic tac toe.
There are 11 tokens.
- 0-8: moves on the board
- 9: start game
- 10: pad
The sequence length is 10, so a game always starts with <9> and can at most fill the board.
Players take turns.
Duplicate moves are illegal.
Generating training data
The universe of valid tic tac toe games is not that big. Only 255 168 variations. I’ve written some python code to enumerate them.
- player 1 wins: 131 184 times
- player 2 wins: 77 904 times
- draw: 46 080 times
From these we can generate a training set of valid game sequences.
[9, 0, 1, 2, 3, 4, 5, 6]
[9, 0, 1, 2, 3, 4, 5, 7, 6, 8]
[9, 0, 1, 2, 3, 4, 5, 7, 8, 6]
[9, 0, 1, 2, 3, 4, 5, 8]
[9, 0, 1, 2, 3, 4, 6, 5, 7, 8]
[9, 0, 1, 2, 3, 4, 6, 5, 8, 7]
[9, 0, 1, 2, 3, 4, 6, 7, 5, 8]
[9, 0, 1, 2, 3, 4, 6, 7, 8, 5]
[9, 0, 1, 2, 3, 4, 6, 8]
[9, 0, 1, 2, 3, 4, 7, 5, 6, 8]
so on...
Pre-training
This data can be used to pre-train our decoder only language model.
For the model we use GPT-2 as implemented by karpathy in https://github.com/karpathy/nanoGPT
For the model parameters let’s go tiny
- block_size: 10
- vocab_size: 11
- n_layer: 1
- n_head: 4
- n_embd: 12
This makes 1896 parameters in total.
The training approach is standard cross entropy loss on the input data. We shift each game sequence once to the left for labels. Each token in every sequence then predicts the next token with masked attention.
This training run is essentially encoding the game of tic tac toe into the transformer.
Set on high GPU for a minute or two…

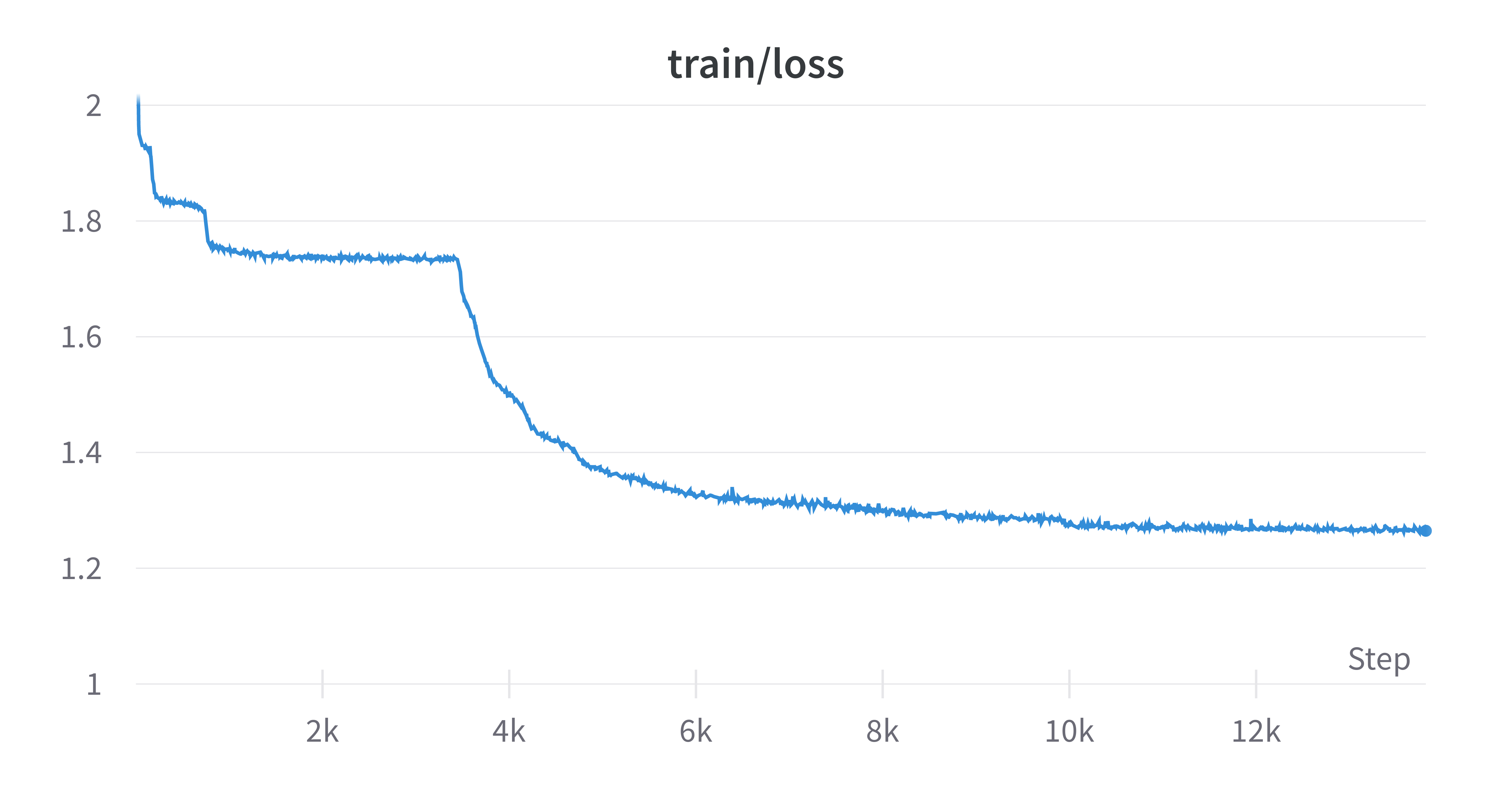
The loss is curious. The model learns a new strategy for encoding the game three times, each time reducing the loss.
Evaluation
We can now run this AI through an evaluation. Let’s see how well the AI can play.
We’ll go easy and let the AI open. If it plays optimally it should win all games.
To evaluate I’ve setup a benchmark of 1000 games. We predict player 1 moves using the model and randomly select a valid move for player 2.
$ python benchmark.py
{'player_2': 359, 'player_1': 472, 'draw': 163, 'invalid': 6}
win_rate: 0.472
The AI wins 47% of the time…
It also predicts 6 invalid moves (duplicate moves).
Fine Tuning with RL
The problem is our model has no incentive to win. It just completes tic tac toe games in the most probable way.
We need to steer the model to be an effective player. Let’s make it an optimal player 1.
We can do this using reinforcement learning.
Similar to tinycatstories, we can rollout a batch of trajectories (game sequences) and score them with a reward function. While rolling out trajectories we keep track of the accumulated log probabilities of predicted tokens. Afterwards we scale the negative of the log probabilities by the reward function.
The reward is
- draw: 0.5
- player 1 wins: 1
- player 2 wins: 0
- invalid token: -0.5
def compute_rewards(sequences):
illegal = batch_detect_illegal_moves(sequences[:, 1:])
valid_sequences = ~illegal
rewards = torch.full(
(sequences.shape[0],), 0.5, device=sequences.device, dtype=torch.float
)
rewards[illegal] = 0
if torch.any(valid_sequences):
boards = batch_seq_to_board(sequences[valid_sequences, 1:])
winners = torch.zeros(
sequences.shape[0], dtype=torch.long, device=sequences.device
)
full = torch.zeros(
sequences.shape[0], dtype=torch.bool, device=sequences.device
)
winners[valid_sequences] = batch_check_winner(boards)
full[valid_sequences] = batch_board_full(boards)
rewards[winners == 1] = 1
rewards[winners == -1] = 0
# incomplete games (due to an invalid move)
incomplete = winners == 0 & ~full
rewards[incomplete] = -0.5
return rewards
With rewards and accumulated log probs we can then use the REINFORCE algorithm to update the model weights.
# Compute loss for the entire batch
neg_advantage = (-normalized_log_probs * rewards.unsqueeze(-1)).mean()
loss = neg_advantage
Set on high GPU for ~2 minutes.
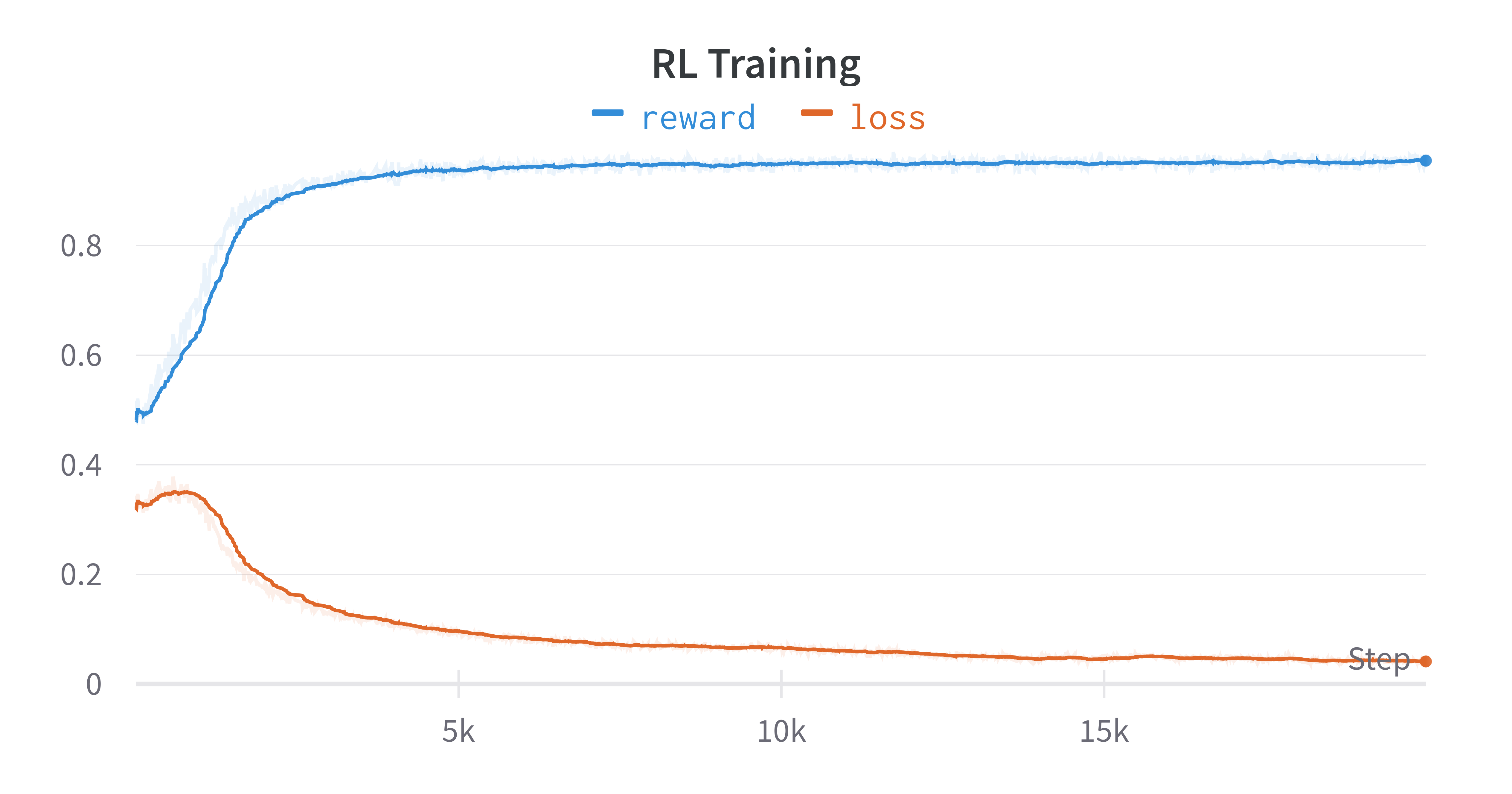
We can see a dramatic shift. The model has gone from 0.5 (draw) to 0.96+
Evaluation
$ python3 benchmark.py
{'player_2': 36, 'player_1': 962, 'draw': 0, 'invalid': 2}
win_rate: 0.962
We now have an AI that wins 96% of the time (against a random opponent). But it will still lose against player 2.
This is close…
SFT
There is something else we can try. What if we supervised fine-tuned the model on all of the optimal game moves? We can enumerate these and build another training set.
The optimal algorithm to win (or at least draw) is to take the following actions (in order of priority):
- take the winning move if it exists
- block the opponent from winning
- take the center
- take any corner
This is more or less the algorithm we want the transformer to learn. (It also has to learn how to keep track of the board state, turn taking, and evaluating a win).
def optimal_moves(board, player):
# Winning moves
moves = winning_moves(board, player)
if moves:
return moves
# Blocking moves
moves = winning_moves(board, -player)
if moves:
return moves
# Center move
if board[1][1] == 0:
return [(1, 1)]
# Corner moves
corners = [(0, 0), (0, 2), (2, 0), (2, 2)]
return [corner for corner in corners if board[corner[0]][corner[1]] == 0]
With the above algorithm we can generate a new training set where player 1 plays optimally and we enumerate all possible futures.
This gives us 408 winning games, and 64 draws. The npy file is approximately 9.4kB.
This approach is more of a compression / memorization. It’s still curious to see how a transformer can learn it.
I played around with a few different configurations.
Eventually using
- block_size: 10
- vocab_size: 11
- n_layer: 1
- n_head: 1
- n_embd: 14
Making a model with 2548 parameters

The resulting benchmark shows it has learned the optimal strategy!
{'player_2': 0, 'player_1': 954, 'draw': 46, 'invalid': 0}
0.954
Either player_1 wins or its a draw!
Success!
We can learn optimal tic tac toe with a ~2548 parameter GPT-2 style transformer.
I think we could probably go smaller, but it would require some hacking of the architecture.
We’re already on the order of magnitude of the equivalent python code required for the same problem (1-2kB).
The dramatic difference is that we didn’t have to analytically solve the game, we just needed data and a language to describe the game.
This opens a curious new future for algorithm design. With the right language, transformers can efficiently learn algorithms.
English language is great, but 2kB transformers are quite a bit faster than 175B monsters…
Exciting potential ahead!