CoDeF
This week, curiosity got the better of me. I spent quite a few early hours of the morning with an A100…
It started when I saw this paper trending on paperswithcode.
Their project site is impressive (at first glance).
Imagine being able to re-watch entire movies in a different visual style, or change the weather or location of your social media post!
So I took a deep dive
How does it work?
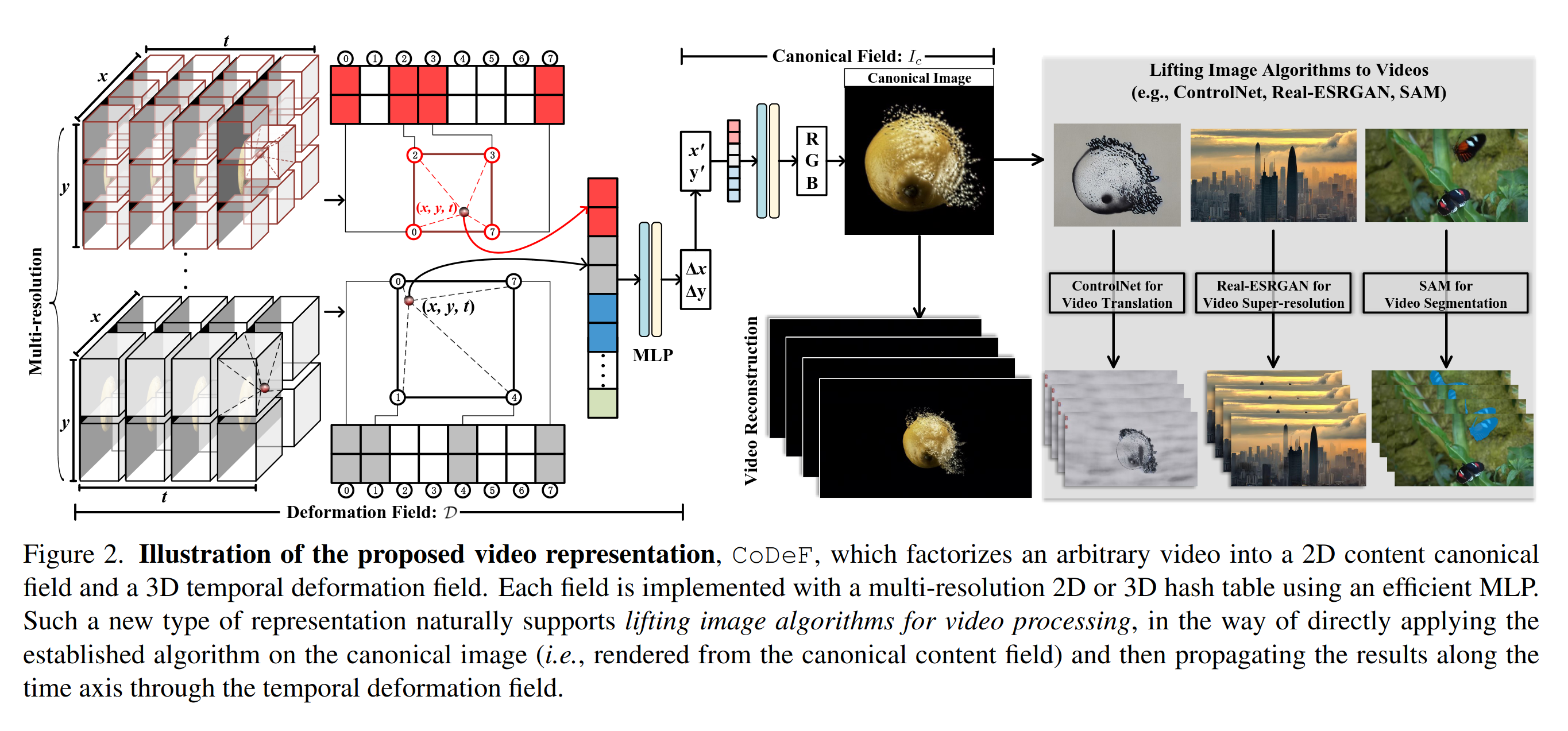
At its core it’s two models
- A model that learns a “canonical” image of the video
- A model that warps this view into each frame
You train these two models jointly on a sequence of video frames.
Once you’re done with training you can sample frames to re-render the video.
If it works well, you can theoretically replace the canonical model with a static texture - and propagate texture edits across the video.
You can also do interesting things like re-sample at different frame rates!
Let’s break it down:
The Warping Model
- A Nerf style MLP
- or a (much faster) 3d HashGrid with a small MLP following
Take a tensor of xy-time (pixel points at time t) and output a grid deformation (x,y) for that point
The Canonical Model
- A Nerf style MLP
- or a (much faster) 2d HashGrid with a small MLP following
Take a tensor of xy (pixel point) and output an rgb color
Now its worth noting that the paper uses two sets of models - one for the background, and one for the foreground. The foreground objects are found by running Segment and Track Anything
Does it work?
Let’s start with their code: https://github.com/qiuyu96/CoDeF
First things first - its a bit of a mess.
There is a lot going on…
- training took 5-10mins for a few seconds of video (on an A100!!)
- no batching
- a million config options
- a lot of branching
- no info on how to generate flow (ipy files)
strange gems like this
class VideoDataset(Dataset):
...
def __len__(self):
return 200 * len(self.all_images)
I really struggled to get any good performance. Mostly my canonical images came out as garbage blurs. There was too much code and control flow for me to make sense of it.
edit: Since writing this blog, their repo is full of similar anecdotal results in the Issues.
I ended up with a canonical images like this

And reconstructed video like this
(original left, reconstructed right)
Reimplement and Experiment
So I pared it down and re-implemented the basics.
https://github.com/pHaeusler/codef-experiments
Focusing on using the HashGrid implementation for both models, and only the foreground
What is the point of the canonical image?
I spend some time trying to get a decent canonical image. Experimenting with regularization losses to encourage the canonical image to be closer to a reference frame.
After a while I really started to question it.
The canonical image doesn’t have to be of anything relevant. It could be a lookup table of random pixel colors. There is no fundamental reason why the canonical image should be a nice framing of the subject of the video. The training strategy tends to optimize to something close (albiet often a blury version) but its not guaranteed. There is a loss function for flow, but AFAICT it just ensures stationary pixels have minimal motion between consecutive deformations, and doesn’t help to maintain consistency of the canonical view.
The pixels in motion don’t have to be sampled from similar locations in the canonical image.
What this means is that you can end up with canonical images that are a crazy super position of motion in the video.

And this is fine for the reconstruction, which is what is minimized. (there are a few translucent artefacts)
But, since we don’t explicitly minimize to preserve a sensible canonical image - we can get nonsense.
Visualizing the deformation map (per frame) during training shows that the warping model samples pixels from multiple locations in the canonical frame. There is a kind of ghosting. No rigidity in the canonical to frame transform.

So why have a canonical model at all? Why not just select a single frame as the base for the deformation?
I tried this a LOT. And, yeah, it kind-of works better. I mean, generally speaking this whole method is fragile.
At least this cuts out a bunch of training time.
Pre-Training
Speaking of training time.
The models spend a bunch of cycles learning how to do basic things.
If we assume the canonical image is the middle frame, then the warping model should apply no warping to all frames and we would have something reasonable to start with.
So we can short-cut this process
- pre-train the warping model to output zeros
- pre-train the implicit video (canonical) model to a target frame
Thoughts along the way..
- HashGrid + tiny MLP don’t produce a very smooth deformation field
- the deformation overfits to the images
- this causes bumpiness during inter-frame interpolation
- There is no loss controlling canonical rigid structure
- The style change must exactly match the shape/contours of the original image or it’s terrible quality
- I got smoother results using a Nerf Style MLP for the warping model from Layered Neural Atlases
- For smooth flow, it helps to train on fewer frames, and let the MLP sample between frames on generation
Here is my shot at style transfer
Training on the beauty_1 dataset from CoDeF
And after changing the canonical image (which in this case was a fixed frame)
I don’t think this make senses
Overall the approach is intellectually interesting… but it’s not super practical.
You have to work hard to find a video sequence that works well for the method.